

Artificial Intelligence vs Machine Learning
Artificial intelligence (AI) is a very broad term used to denote the intelligence demonstrated by smart machines which are capable of performing tasks that typically require human intelligence. It is also used to describe the branch of engineering concerned with building such smart machines.
On the other hand, Machine Learning (ML) is a subset of artificial intelligence. ML uses different computer algorithms such as neural networks to enable the computer to automatically learn and improve from experience without being explicitly programmed. ML can be further divided into supervised learning, unsupervised learning and reinforcement learning.
Today, there is also another branch of learning called Deep Learning. It is a subset of machine learning, which uses the neural networks to analyze different factors with a structure that is similar to the human neural system. Artificial Intelligence applies machine learning, deep learning and other techniques to solve actual problems.
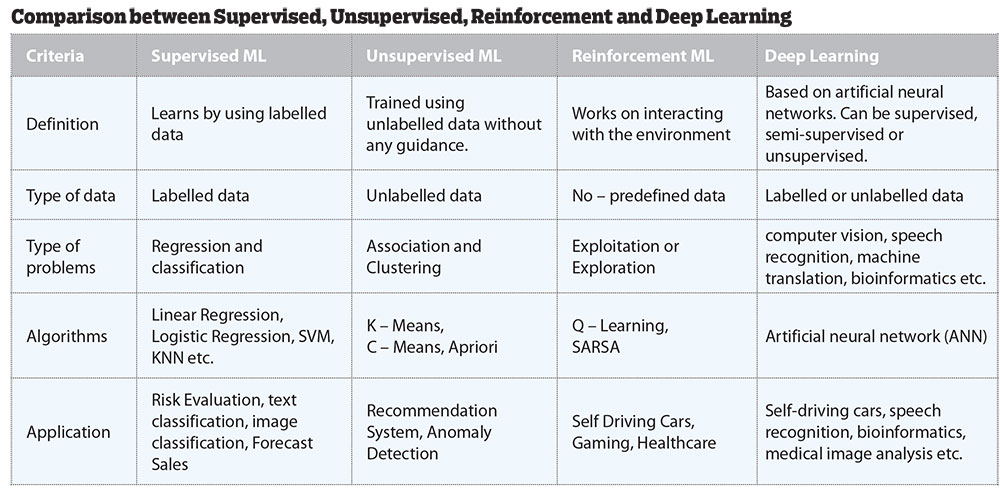
Supervised ML and Unsupervised ML
Supervised learning is a machine learning approach that depends on the use of labeled datasets, also called annotated datasets. These datasets are designed to train or “supervise” algorithms into classifying data or predicting outcomes accurately.
Here is a simple example. An automatic email spam identifier is trained by providing annotated spam emails as examples. The next time it seems an email that is similar to the examples it has been fed beforehand, it straight away sends the email to the spam folder. Similarly, automatic MRI scanners can be trained to identify tumors and other medical anomalies.
So, supervised learning uses annotated or labelled input and output data, while an unsupervised learning algorithm does not. While supervised learning models tend to be more accurate than unsupervised learning models, they require upfront human intervention to label the data appropriately. Unsupervised learning models, in contrast, work on their own to discover the inherent structure of unlabelled data. But unsupervised learning could still require some human intervention for validating output variables.
Supervised learning is used for spam detection, sentiment analysis, weather forecasting and pricing predictions, etc. while unsupervised learning is used for anomaly detection, recommendation engines, customer personas and medical imaging etc.
Reinforcement Learning
RL algorithms learn to react to an environment on their own, adapting to the environment it encounters. It uses a learning agent which has a start state and an end state. The agent travels from one state to another and gets the reward (appreciation) on success but will not receive any reward or appreciation on failure. In this way, the agent learns from the environment. It is neither based on supervised learning nor unsupervised learning. RL algorithms are used in Robotics, Gaming etc.
Data Annotation for ML
Data annotation is the process of labeling data to show the outcome you want your machine learning model to predict. People engaged in the process do the marking – labeling, tagging, transcribing, or processing – a dataset with the features you want your machine learning system to learn to recognize. For example, in iMerit Technologies at Thimphu TechPark, employees annotate a larget set of pictures of farmland to help drones or other machines that spray weedicide identify weeds from the crops. Annotated data reveals features that will train the algorithms to identify the same features in data that has not been annotated. Data annotation is used in supervised learning and hybrid, or semi-supervised, machine learning models that involve supervised learning.
Jobs created by ML at Thimphu TechPark
As mentioned earlier, supervised machine learning requires the data to be labelled by humans in advance in order for the machine to be able to learn. The act of labelling the data is called data annotation. With the rise in interest in ML and AI, demand for data annotation has increased in recent times, and many companies providing data annotation services have come into existence. iMerit Technologies, a FDI company based in Thimphu TechPark, with headquarters in the US is one of the well known companies in this sector.
iMerit Bhutan was launched on 28th August 2019 with a team of about 130 employees. It has now grown to around 250 employees. They work on data annotation services which include annotating textual data for natural language processing, image data for image recognition/classification and video data for computer vision. The company exports 100% of its services.
During the launch, Jai Natarajan, the Vice President for Marketing and Strategic Business Development, iMerit, said, “We offer data services to global companies around the world. Those companies are using this data to solve some very difficult problem using technology. This problem includes how to get a car to drive itself without a driver or how to automatically detect diseases from medical images like x-rays and MRIs. Another example of this can be how to find the pollution and destruction of the forest from the satellite images.”
Similarly, ScanCafe, one of the first major companies to come to Thimphu TechPark, have been employing hundreds of Bhutanese youths since 2013 for its photo editing and photo book design services, all of which are exported to clients outside Bhutan. At its peak in 2016-2017, it employed around 500 people. But today, with better automation, the number of employees have come down. The better automation is achieved by Machine Learning and AI, based on the examples provided by human photo editors and photobook designers.
Opportunities for Bhutan
AI and ML are hot fields of technology that is finding applications in various fields from customer service and marketing to machine translation and self-driving cars. We can definitely explore ways to use it to solve various problems we face in Bhutan, including automating mundane tasks. For offices having to deal with large amounts of textual data, it can be used for text classification and text summarization etc. Furthermore, promoting Research and Development in the field would never be too late. Opportunities also exist for providing data annotation services and create more employment opportunities for our youth.